
by: attorney Víctor M. Rodríguez-Reyes
As generative AI becomes increasingly integrated into content creation, understanding its mechanics and leveraging unique approaches can help brands maintain a distinct voice. In this blog, I share the principles behind generative AI and offer practical tips to ensure your content remains original and impactful. From niche-focused topics to proprietary data, discover how your organization can stay ahead in the AI-driven ecosystem while preserving the quality and uniqueness of its messaging.
Generative artificial intelligence can be compared (simplifying a lot!) with a word cloud, like the one above.
This word cloud was generated with the words used in my video.
A word cloud uses parameters to create a visual representation of word usage within content.
Some of these parameters might include:
- Proximity: how close (or far) each word is from others.
- Quantity: how many times each word appears in the content.
Generative AI uses concepts similar to these parameters to organize human language using a model whose structure simulates the brain and contains interconnected nodes (or neurons), known as neural networks. As with human knowledge in general, the neural network generated is limited by the words that make up the model.
Three proven strategies to protect legal content from AI
In my second video on Artificial Intelligence, I propose three tips to prevent these systems from replacing your content. Here, I’ll provide a brief demonstration of these three principles using ChatGPT-4.
1. Niche Content.
Prompt used in ChatGPT: Who wins trade secret litigations in Puerto Rico?
To test ChatGPT’s response, I used a niche topic of interest to me: trade secret litigation! The prompt is deliberately broad to test the interaction between the question and the results.
Interestingly, the response varies depending on the language of the prompt. When asked in English, the abbreviated answer was as follows:

It’s not entirely coincidental that Ferraiuoli appeared in this response; it results from using a prompt limited to a niche subject. The chosen prompt aimed to gather information on parties involved in such cases (plaintiff vs. defendant, types of companies, etc.). However, the Ferraiuoli website is one of those with the most content on this prompt topic and, therefore, ChatGPT uses it in its search:
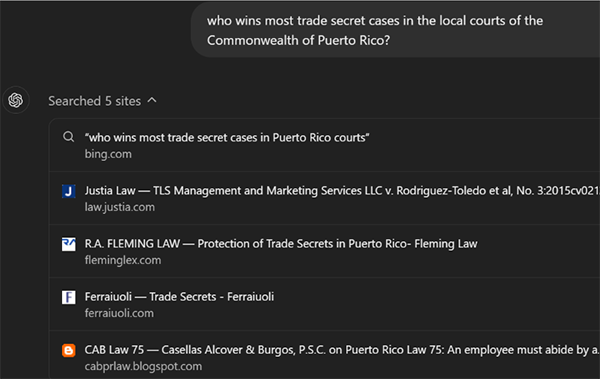
Note that, in this case, we didn’t prevent ChatGPT from using Ferraiuoli’s generated content; however, the importance of that content within the niche compels ChatGPT to create an auto-referential response to Ferraiuoli’s content.
One of the reasons for this is the use of terms like “Commonwealth,” “Puerto Rico,” and “local courts,” which do not commonly appear together in the content used to train ChatGPT. As a result, this 4th version seeks available authoritative sources on the internet to generate its response. Contrary to what one might think, the result is not a copy of any of the visited websites’ content but rather a combination of this and ChatGPT’s Large Language Model. Proof of this is that generic prompts do not involve website searches and yield responses that do not cite any sources.

Recommended for You: Intellectual Property 101 – A Quick Guide
2. Contrarian Content (Hot Takes)
Prompt used in ChatGPT: In Major League Baseball, the Chicago White Sox are the team most likely to win the 2025 World Series.
In this example, we used a false statement since the White Sox finished with the worst record this season. The result is that ChatGPT takes a position contrary to what the prompt suggests:

The point of this advice is not simply to be contrarian for content creation’s sake, but to explore widely accepted topics that might require further analysis as an avenue to generate more differentiated output.
3. Content Based on Proprietary Data.
Prompt used in ChatGPT: How many lawsuits were filed in Corozal by someone with the last name Rodriguez.
In this case, the prompt refers to information that has not been publicly available to date, and the result is null, although ChatGPT manages to identify possible ways to obtain the information:

This advice aims to use information not easily available online to add value for the content consumer in a way AI systems cannot easily replicate. In the end, that’s what separates good content from the rest—its independence and originality, its resistance to easy substitution.
The Role of Proprietary Data in Protecting Content Uniqueness
As the role of generative AI in content creation continues to evolve, businesses must stay ahead by leveraging unique, data-driven insights and niche expertise. By understanding how AI interacts with information and applying strategic approaches, companies can maintain a distinct voice that resonates with their audience, even in an increasingly automated world. At Ferraiuoli, we’re committed to guiding our clients through these transformative changes, ensuring they harness innovation while safeguarding originality and intellectual property. In a rapidly shifting AI-powered environment, adaptability and expertise will set the leaders apart from the rest.
Protect your legal content in AI, schedule a consultation with me, IP expert, to develop your AI-proof content strategy.
About the Author
Victor Rodríguez-Reyes, Esq., Senior Member of Ferraiuoli, is a seasoned attorney in Intellectual Property practice, specializing in the intersection of technology and law. With extensive experience advising clients on cutting-edge issues, Victor is passionate about exploring how emerging technologies, like generative AI, are reshaping industries. His insights offer practical guidance for companies exploring the evolving world of artificial intelligence and intellectual property





